Anatomy of an Alexa Skill
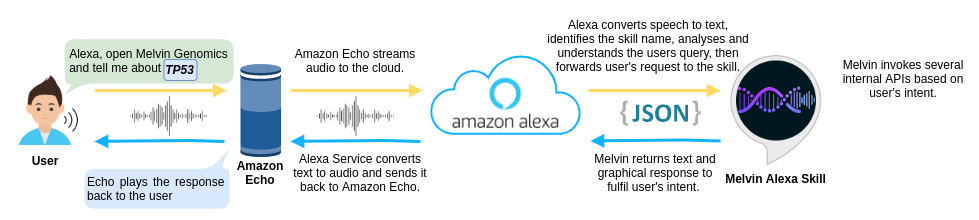 This figure illustrates a flow of how a user’s speech is processed by an Amazon Echo device and how a response is created by a skill. Continue reading to understand what's happening behind the scenes.
This figure illustrates a flow of how a user’s speech is processed by an Amazon Echo device and how a response is created by a skill. Continue reading to understand what's happening behind the scenes.
Conversation Initiation#
There are two approaches to initiate a conversation with Alexa, which is determined by the type of device where it runs. On smartphones it’s invoked by pressing on a dedicated button in the Alexa application. On smart speakers, like Echo, the microphones are always enabled and listening to the surroundings. As soon as they hear a wake word (or phrase), the device goes into a conversational mode. The default wake word on Alexa-enabled devices is "Alexa". Once the wake word detection occurs on the device, the device starts streaming all incoming voice signals to the cloud, where those signals are to be processed by Automatic Speech Recognition (ASR).
Automatic Speech Recognition (ASR)#
The main objective of Alexa ASR is to transform voice signals into text. Beyond this, it handles different challenges such as speed of talking (slow vs. fast), volume (loud vs. quiet), clarity of speech (mumbling, accents, distortion of consonants), background noises, slang words and archaisms. Combining three analysis models -- lexicon, acoustic and language -- together helps ASR deal with the speech recognition challenges and allows it to decode the voice signal into the text with a high degree of precision. The ASR engine then sends the decoded words to the Natural Language Understanding (NLU) module.
Natural Language Understanding (NLU)#
The NLU module understands the users’ intentions and the current context. It is typically a well-trained model that knows grammar rules of the language, is able to recognize the relationships between words, and extract the named entities. In practice, the NLU module is used on top of the skill’s interaction model to match the user’s speech with a corresponding intent, fill in the slot values, and pass the structured data to the fulfillment.
Interaction Model#
The interaction model is the foundation of any voice application. It provides all necessary information for the computer to understand and process the voice request. This information consists of invocation names, intents, sample utterances, and slots. After the intent is recognized and all required values are collected, the system can either respond back immediately or send the data together with the resolved slot values to the corresponding intent’s handler to execute some additional logic.
Text to speech#
Text-to-speech, also known as speech synthesis, is the ability of a machine to read the written text. This process is opposite to the ASR.
SSML#
Speech Synthesis Markup Language is an XML-based markup language recommended by the W3C’s voice browser working group as a tool to provide guidance on how the machine should generate the speech. It allows controlling intonation, emphasis, rate of speech, and pronunciation.